So sánh chi tiết Kafka (distributed log) vs Redis (in-memory cache), khi nào dùng từng công nghệ, cách kết hợp trong kiến trúc event-driven 2026
Kafka vs Redis: Chọn Công Nghệ Nào Cho Xử Lý Dữ Liệu Real-Time
Khi hệ thống xử lý hàng triệu sự kiện mỗi giây, việc chọn sai giữa Kafka và Redis có thể dẫn đến mất dữ liệu, bottleneck nghiêm trọng hoặc lãng phí tài nguyên. Cả hai công nghệ đều là các trụ cột trong kiến trúc dữ liệu hiện đại, nhưng chúng giải quyết những bài toán hoàn toàn khác nhau. Bài viết này phân tích sâu kiến trúc, điểm mạnh, điểm yếu và kịch bản sử dụng tối ưu của từng công nghệ, giúp bạn ra quyết định kỹ thuật đúng đắn.
Kafka là gì? Kiến Trúc Phân Tán Và Cơ Chế Hoạt Động
Apache Kafka được xây dựng từ nền tảng của một distributed log system. Khác với hệ thống hàng đợi tin nhắn truyền thống, Kafka sử dụng mô hình pull-based, nghĩa là consumer chủ động kéo dữ liệu từ broker thay vì broker đẩy dữ liệu đến consumer. Điều này cho phép consumer kiểm soát tốc độ tiêu thụ dữ liệu thông qua offset, tức là vị trí lần cuối cùng mà consumer đã xử lý.
Kiến trúc Apache Kafka với Producer, Broker, Topic Partition và Consumer Group - nguồn từ Viblo.asia
Kiến trúc Kafka bao gồm ba thành phần chính. Producer là ứng dụng hoặc dịch vụ gửi dữ liệu vào các topic. Broker là máy chủ Kafka lưu trữ dữ liệu được chia thành các partition, mỗi partition là một log file theo thứ tự. Consumer Group là một nhóm các consumer có thể đọc song song từ các partition khác nhau của cùng một topic.
Ưu điểm lớn nhất của Kafka là khả năng lưu trữ dữ liệu lâu dài và cho phép replay bất kỳ lúc nào. Bạn có thể cấu hình Kafka giữ lại dữ liệu trong vài giờ, vài ngày, hoặc thậm chí vô hạn. Khi có lỗi hoặc cần xử lý lại dữ liệu, consumer có thể reset offset và phát lại từ bất kỳ thời điểm nào trong lịch sử. Kafka cũng hỗ trợ ngữ nghĩa exactly-once processing, đảm bảo mỗi sự kiện được xử lý chính xác một lần mà không bị lặp hoặc mất.
Theo BizFly Cloud, Kafka có khả năng xử lý vượt quá 100.000 tin nhắn mỗi giây với độ trễ thấp. Nó cũng hỗ trợ payload lên đến 1GB sau khi nén, phù hợp với các use case xử lý log lớn, sự kiện IoT, hoặc dữ liệu giao dịch tài chính. Kiến trúc phân tán với replication đảm bảo rằng nếu một broker bị lỗi, dữ liệu vẫn được bảo vệ trên các broker khác.
Redis là gì? In-Memory Store Và Sức Mạnh Độ Trễ Cực Thấp
Redis là một in-memory key-value store, đồng nghĩa với việc tất cả dữ liệu được lưu trữ trên RAM thay vì đĩa. Khi bạn đọc hoặc ghi dữ liệu trong Redis, thời gian phản hồi được tính bằng millisecond, thậm chí microsecond trong một số trường hợp. Tốc độ này xuất phát từ việc truy cập trực tiếp trên bộ nhớ mà không cần thao tác I/O đĩa như các cơ sở dữ liệu truyền thống.
Tổng quan kiến trúc Redis in-memory và mô hình Pub/Sub - nguồn từ BizFly Cloud
Redis không phải chỉ là một cơ sở dữ liệu đơn giản. Nó hỗ trợ nhiều cấu trúc dữ liệu phong phú: String, Hash, List, Set, Sorted Set, và cả Stream. Mỗi cấu trúc có các lệnh tối ưu riêng biệt, cho phép bạn giải quyết các vấn đề phức tạp mà không cần phải viết code phức tạp.
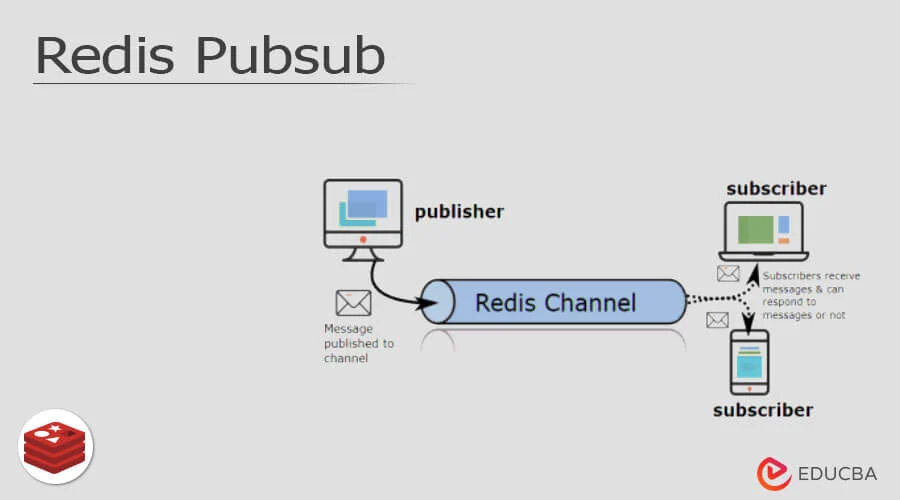
Về Pub/Sub, Redis cung cấp một mô hình push-based đơn giản: publisher gửi tin nhắn đến một channel, và các subscriber lắng nghe trên channel đó sẽ nhận tin nhắn ngay lập tức. Điểm yếu chí mạng ở đây là Redis tự động xóa tin nhắn sau khi gửi đến subscriber. Nếu subscriber chưa kết nối tại thời điểm gửi, tin nhắn sẽ mất mãi mãi. Theo Viblo.asia, Redis Pub/Sub chỉ hỗ trợ ngữ nghĩa at-most-once, không đảm bảo tin nhắn được nhận.
Điểm khác biệt quan trọng là Redis 2025 đã quay trở lại mô hình open-source hoàn toàn với tri-license AGPLv3. Trước đó, Redis đã chuyển sang dual-license vào 2024, gây lo ngại cho các doanh nghiệp về quyền sử dụng. Sự thay đổi này ảnh hưởng đến chiến lược lựa chọn công nghệ của nhiều tổ chức, đặc biệt là những doanh nghiệp vốn muốn tránh các rủi ro pháp lý liên quan đến licensing.
So Sánh Kafka Vs Redis: Bảng Đối Chiếu Toàn Diện
Trước khi đi vào chi tiết, hãy nhìn vào bảng so sánh nhanh giữa hai công nghệ theo các tiêu chí kỹ thuật quan trọng.
Bảng so sánh chi tiết Kafka và Redis theo các tiêu chí kỹ thuật - nguồn từ BizFly Cloud
| Tiêu chí | Kafka | Redis |
|---|---|---|
| Mô hình nhắn tin | Pull-based (consumer kiểm soát offset) | Push-based (broker đẩy dữ liệu) |
| Độ trễ | Thấp (millisecond) nhưng không tối ưu cho real-time tức thì | Cực thấp (millisecond từ RAM) |
| Throughput | Vượt 100.000 msg/s, tối ưu cho dữ liệu lớn | Cao nhưng thường chỉ cho single-node hoặc cluster nhỏ |
| Độ bền dữ liệu | Lưu trữ dài hạn, cho phép replay | Không lưu trữ khi subscriber chưa kết nối (Pub/Sub) |
| Message guarantee | Exactly-once, At-least-once | At-most-once (Pub/Sub) |
| Kích thước tin nhắn | Đến 1GB sau nén | Chỉ phù hợp payload nhỏ |
| Consumer groups | Hỗ trợ, cho phép song song hóa | Không hỗ trợ (Pub/Sub) |
| Persistence | Mặc định lưu lâu dài trên disk | Tùy chọn (RDB, AOF) |
| Scalability | Ngang (thêm partition và consumer) | Dọc (thêm RAM) |
| Use case chính | Event streaming, log, analytics | Cache, session, real-time counter |
Sự khác biệt cơ bản nhất nằm ở mục đích thiết kế: Kafka được xây dựng để xử lý các luồng dữ liệu khổng lồ với độ bền cao, trong khi Redis được xây dựng để cung cấp truy cập tức thì với độ trễ cực thấp.
Khi Nào Chọn Kafka? Khi Nào Chọn Redis?
Việc lựa chọn giữa Kafka và Redis không nên dựa trên hype hoặc lượt download, mà phải căn cứ vào các yêu cầu cụ thể của hệ thống.
So sánh use case thực tế giữa Kafka và Redis trong hệ thống phân tán - nguồn từ Viblo.asia
Chọn Kafka khi bạn cần:
Kafka là lựa chọn tối ưu khi bạn xây dựng pipeline dữ liệu quy mô lớn, chẳng hạn như hệ thống log tập trung nơi hàng triệu ứng dụng phía máy chủ hoặc điểm bán hàng gửi log về một nơi. Nó cũng phù hợp cho các ứng dụng IoT thu thập dữ liệu từ hàng nghìn cảm biến. Trong lĩnh vực tài chính, Kafka được sử dụng rộng rãi cho việc ghi lại các giao dịch, báo cáo thay đổi giá và xử lý dòng sự kiện từ các sàn giao dịch.
Kafka là trung tâm của các kiến trúc event-driven microservices hiện đại, nơi mỗi dịch vụ sản sinh hoặc tiêu thụ các sự kiện từ các topic chung. Khả năng replay dữ liệu cũng rất quan trọng nếu bạn cần audit trail hoặc muốn học lại từ dữ liệu lịch sử sau khi phát hiện một lỗi xử lý.
Chọn Redis khi bạn cần:
Redis là lựa chọn hoàn hảo cho các bài toán yêu cầu độ trễ cực thấp. Một ví dụ điển hình là caching lớp phía trước (front cache) cho các API tải cao, nơi mỗi millisecond đều quan trọng đối với trải nghiệm người dùng. Redis cũng được dùng cho session management trong các ứng dụng web, nơi mỗi yêu cầu HTTP cần kiểm tra nhanh session của người dùng.
Trong gaming, Redis được sử dụng để quản lý leaderboard real-time và ranking, nơi hàng trăm nghìn người chơi cập nhật điểm số của họ mỗi giây. Với cấu trúc Sorted Set, Redis có thể trả về top 100 người chơi trong millisecond mà không cần query cơ sở dữ liệu. Nó cũng phù hợp cho phát hiện gian lận real-time, nơi bạn cần kiểm tra ngay lập tức xem một giao dịch có hợp lệ hay không dựa trên các mẫu hành vi đã lưu.
Anti-pattern cần tránh:
Một sai lầm phổ biến là dùng Redis Pub/Sub làm message broker chính trong các hệ thống yêu cầu độ bền dữ liệu cao. Redis Pub/Sub không lưu lại dữ liệu, và nếu subscriber đang down lúc có tin nhắn, dữ liệu sẽ mất vĩnh viễn. Đây là nguyên nhân dẫn đến mất dữ liệu trong production nếu không cẩn thận.
Ngược lại, dùng Kafka cho những bài toán đơn giản như caching hoặc session management là lãng phí. Kafka đòi hỏi nhiều tài nguyên hơn để cài đặt, cấu hình và duy trì so với một Redis instance đơn giản.
Lựa chọn trung gian: Redis Streams
Redis Streams (không phải Pub/Sub) là một giải pháp trung gian. Nó có persistence, consumer groups tương tự Kafka, nhưng thiếu khả năng scale ngang của Kafka. Redis Streams phù hợp cho các hệ thống nhỏ đến trung bình nơi bạn cần persistence nhưng không cần khả năng scale đến hàng triệu message/giây.
Kiến Trúc Kết Hợp Kafka + Redis: Giải Pháp Tối Ưu Cho Hệ Thống Hiện Đại
Quan điểm cổ điển rằng bạn phải chọn Kafka HOẶC Redis là sai lệch. Trong thực tế, năm 2026, các kiến trúc hệ thống tốt nhất thường kết hợp cả hai công nghệ theo một mô hình phân lớp rõ ràng.
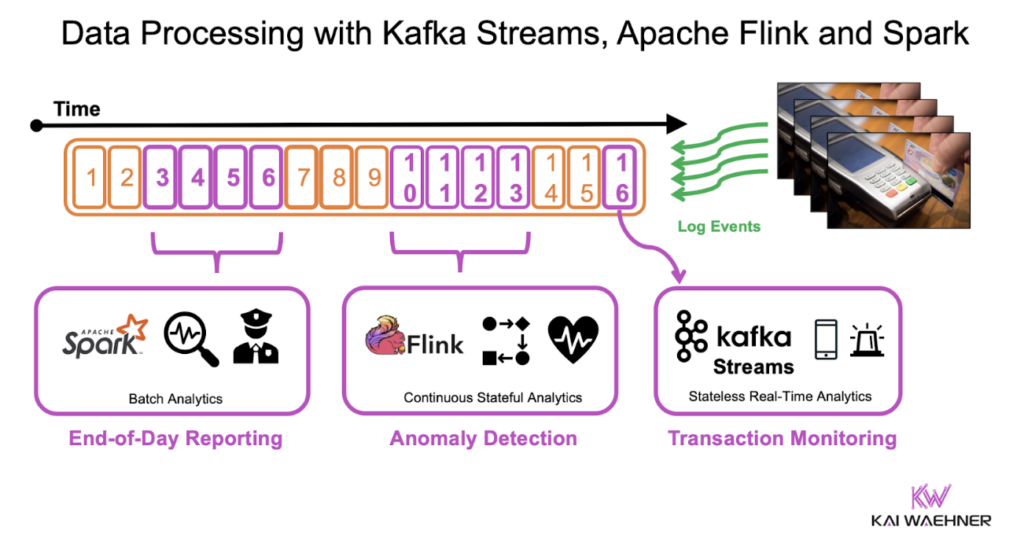
Kiến trúc kết hợp xử lý stream và batch với Kafka Streams, Apache Flink và Spark - nguồn từ Kai Waehner Blog
Mô hình hybrid điển hình:
Kafka đóng vai trò là "data backbone" của hệ thống. Nó ingest dữ liệu từ hàng triệu producer và xử lý các luồng sự kiện thô. Sau khi xử lý với Kafka Streams hoặc Apache Flink, các kết quả tính toán được đẩy vào Redis để phục vụ lớp truy xuất nhanh cho người dùng cuối.
Ví dụ cụ thể: Một nền tảng e-commerce nhận hàng triệu sự kiện click sản phẩm mỗi ngày. Kafka lưu trữ toàn bộ các sự kiện này. Apache Flink xử lý các sự kiện và tính toán real-time analytics, chẳng hạn như "sản phẩm nào đang trending ngay bây giờ". Kết quả tính toán (top 100 trending products) được ghi vào Redis. Khi người dùng truy cập trang chủ, API phía máy chủ đọc từ Redis để hiển thị trending products với độ trễ cực thấp.
Kafka + Flink: Xử Lý Stateful Với Exactly-Once Semantics
Apache Flink là một stream processing framework mạnh mẽ. Khi kết hợp Kafka (data source) với Flink (processing engine) và Redis (state store), bạn có được một hệ thống xử lý sự kiện phức tạp với degree cao về tin cậy.
Flink duy trì trạng thái (state) của các tính toán, chẳng hạn như "số lượng đơn hàng từ người dùng X trong vòng 1 giờ qua". Khi xảy ra lỗi, Flink có thể phục hồi trạng thái từ checkpoint và tiếp tục xử lý từ điểm dừng mà không bị mất dữ liệu hoặc xử lý lặp. Điều này thể hiện ngữ nghĩa exactly-once mà các hệ thống thanh toán hoặc tài chính không thể chịu được mà không có.
Kafka + Quarkus: Event-Driven Cloud-Native
Quarkus là một framework Java hiện đại được tối ưu cho Kubernetes và serverless. Nó cung cấp Reactive Messaging, một abstraction đơn giản hóa việc viết producer/consumer Kafka.
@ApplicationScoped
public class OrderProcessor {
@Incoming("orders")
@Outgoing("processed-orders")
public ProcessedOrder processOrder(Order order) {
// Xử lý đơn hàng
return new ProcessedOrder(order.getId(), order.getAmount() * 0.95);
}
}
Ở đây, @Incoming("orders") lắng nghe từ topic Kafka "orders", và @Outgoing("processed-orders") gửi kết quả đến topic Kafka khác. Quarkus tự động quản lý kết nối, offset, và error handling. Framework này được thiết kế để khởi động nhanh (startup time dưới 1 giây) và tiêu thụ ít bộ nhớ, phù hợp cho các môi trường containerized hoặc serverless.
Nguyên Tắc Thiết Kế: Partition Parallelism Alignment
Một nguyên tắc quan trọng khi kết hợp Kafka và Flink là căn chỉnh số lượng partition Kafka với số lượng task Flink. Nếu bạn có 10 partition trong topic Kafka, bạn nên cấu hình Flink parallelism là 10. Điều này đảm bảo rằng mỗi task Flink xử lý chính xác một partition, tránh việc overload một task trong khi task khác nhàn rỗi.
Xu Hướng 2026: Diskless Kafka, Agentic AI Và Tương Lai Streaming
Kiến trúc dữ liệu real-time không đứng yên. Năm 2026 chứng kiến những thay đổi quan trọng trong cách chúng ta xây dựng hệ thống stream processing.

Xu hướng Data Streaming 2026: Kafka, Flink, Diskless Cloud và Agentic AI - nguồn từ Kai Waehner Blog
Diskless Kafka: Tách Biệt Compute Từ Storage
Kafka truyền thống yêu cầu broker phải có disk lớu để lưu trữ dữ liệu. Diskless Kafka là một xu hướng mới, nơi Kafka offload dữ liệu từ broker disk sang cloud object storage như AWS S3 hoặc Azure Blob Storage. Broker chỉ giữ lại một phần dữ liệu gần đây trong cache, và dữ liệu cũ được lưu trên object storage.
Cách tiếp cận này mang lại những lợi ích to lớn. Thứ nhất, chi phí cơ sở hạ tầng giảm đáng kể vì bạn không cần phải mua những chiếc server với disk lớn. Thứ hai, khả năng mở rộng đàn hồi cải thiện: bạn có thể nhanh chóng thêm hoặc bớt broker mà không lo lắng về capacity disk. Thứ ba, disaster recovery trở nên đơn giản hơn vì dữ liệu đã được lưu trên cloud storage có built-in redundancy.
Diskless Kafka thường được kết hợp với Apache Iceberg, một định dạng bảng phân tán cho object storage. Iceberg cung cấp ACID transactions, schema evolution, và time travel query, cho phép bạn query dữ liệu lịch sử từ bất kỳ thời điểm nào.
Agentic AI: Kafka + Flink Cung Cấp Real-Time Context
Một xu hướng khác đang nổi lên là Agentic AI, nơi các AI agent tự động ra quyết định dựa trên thông tin real-time. Theo Kai Waehner, một chuyên gia hàng đầu về Kafka, "data streaming và kiến trúc event-driven của nó trở thành nền tảng cung cấp context, trạng thái và sự phối hợp mà các AI agent cần".
Hãy tưởng tượng một agent AI được giao nhiệm vụ tối ưu hóa chuỗi cung ứng. Agent này cần truy cập dữ liệu real-time về độ trễ giao hàng, chi phí vận chuyển, và tình trạng kho hàng. Kafka cung cấp luồng liên tục của các sự kiện này, Flink xử lý và tính toán các metric, và Redis lưu trữ trạng thái hiện tại. Agent AI query Redis để lấy trạng thái mới nhất, đưa ra quyết định (chẳng hạn như "gửi hàng từ kho nào"), và các quyết định này lại được feed vào Kafka dưới dạng sự kiện để phát hiện các vấn đề hoặc lệnh điều khiển.
Sự tích hợp này giữa Kafka, Flink, Redis, và Agentic AI đang định hình lại nền tảng dữ liệu của những doanh nghiệp tiên phong.
Consolidation Trend: Unified Platform
Các nền tảng streaming lớn như Confluent Cloud, AWS MSK, và Azure Event Hubs đang tích hợp ngày càng nhiều chức năng vào một nền tảng thống nhất. Chúng không chỉ cung cấp Kafka mà còn kèm theo stream processing, API gateway, governance, và monitoring. Xu hướng này giảm độ phức tạp vận hành và cho phép team nhỏ quản lý hạ tầng streaming phức tạp mà không cần chuyên gia Kafka chuyên dụng.
Zero Data Loss SLA: Synchronous Multi-Region Replication
Nhiều doanh nghiệp ngày nay đòi hỏi zero data loss SLA (Service Level Agreement). Điều này có nghĩa là khi producer ghi dữ liệu vào Kafka, dữ liệu phải được replicate đồng bộ tới nhiều region trước khi acknowledge trở lại producer. Mặc dù điều này làm tăng độ trễ write, nhưng đó là đánh đổi chấp nhận được cho các hệ thống tài chính hoặc e-commerce quan trọng.
Hướng Dẫn Triển Khai Thực Tế: Event-Driven Với Kafka Và Quarkus
Để hiểu rõ hơn cách kết hợp Kafka và Redis trong thực tế, hãy xem qua một ví dụ triển khai kiến trúc event-driven đơn giản sử dụng Quarkus.
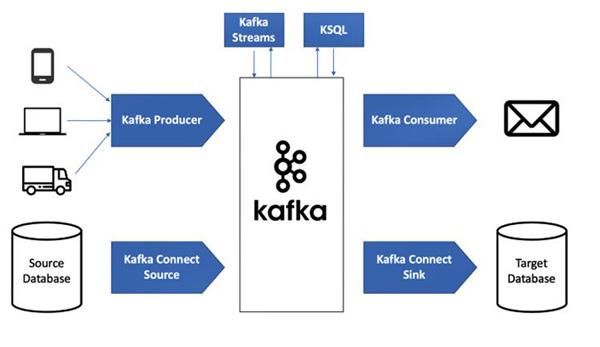
Kiến trúc event-driven với Apache Kafka và Quarkus trong môi trường cloud-native - nguồn từ Viblo.asia
Bước 1: Thiết Lập Cấu Hình Kafka
Tạo file application.properties để cấu hình kết nối Kafka:
kafka.bootstrap.servers=localhost:9092
mp.messaging.incoming.orders.connector=smallrye-kafka
mp.messaging.incoming.orders.topic=orders
mp.messaging.incoming.orders.group.id=order-processor-group
mp.messaging.incoming.orders.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.outgoing.processed-orders.connector=smallrye-kafka
mp.messaging.outgoing.processed-orders.topic=processed-orders
mp.messaging.outgoing.processed-orders.value.serializer=org.apache.kafka.common.serialization.StringSerializer
Cách tiếp cận này tách biệt cấu hình kết nối khỏi business logic. Nếu bạn muốn thay đổi Kafka broker address hoặc topic name, chỉ cần chỉnh sửa file properties mà không cần recompile code.
Bước 2: Viết Order Processor
Tạo một class xử lý đơn hàng:
@ApplicationScoped
public class OrderProcessor {
@Inject
RedisClient redis;
@Incoming("orders")
@Outgoing("processed-orders")
public Message<String> processOrder(Message<String> orderMessage)
throws JsonProcessingException {
String orderJson = orderMessage.getPayload();
Order order = new ObjectMapper().readValue(orderJson, Order.class);
// Kiểm tra trong Redis xem người dùng đã đạt hạn mức mua chưa
String userLimit = redis.get("user_limit_" + order.getUserId());
if (userLimit != null && Double.parseDouble(userLimit) < order.getAmount()) {
orderMessage.nack(new Exception("User exceeded purchase limit"));
return null;
}
// Xử lý đơn hàng
order.setStatus("PROCESSING");
order.setProcessedAt(Instant.now());
// Cập nhật Redis với thông tin đơn hàng mới nhất (cho dashboard real-time)
redis.set("order_" + order.getId(), new ObjectMapper().writeValueAsString(order));
redis.expire("order_" + order.getId(), 3600); // TTL 1 giờ
String processedJson = new ObjectMapper().writeValueAsString(order);
return Message.of(processedJson);
}
}
Lưu ý cách code sử dụng Kafka để nhận đơn hàng thô từ topic orders, sau đó truy cập Redis để kiểm tra hạn mức người dùng. Sau khi xử lý, kết quả được ghi vào cả Kafka (topic processed-orders) và Redis (để dashboard quản lý có thể truy cập thông tin đơn hàng mới nhất).
Bước 3: Chạy Với Docker Compose
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:7.5.0
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
redis:
image: redis:7.0-alpine
ports:
- "6379:6379"
Chạy lệnh:
docker-compose up -d
Bước 4: Triển Khai Ứng Dụng Quarkus
./mvnw clean quarkus:dev
Ứng dụng sẽ khởi động nhanh chóng và sẵn sàng nhận đơn hàng từ topic Kafka. Trong develop mode, bạn có thể thay đổi code và thấy thay đổi tức thì mà không cần restart.
Vì Sao Quarkus Phù Hợp Cho Event-Driven Architecture:
Quarkus được thiết kế cụ thể cho cloud-native applications. Startup time dưới 1 giây và memory footprint dưới 100MB làm cho nó lý tưởng cho các microservices được triển khai trên Kubernetes. Khi bạn có hàng chục microservices event-driven, sự hiệu quả này tích lũy và dẫn đến tiết kiệm chi phí hạ tầng đáng kể.
Ngoài ra, Quarkus Reactive Messaging tự động xử lý backpressure (khi producer tạo ra dữ liệu nhanh hơn consumer có thể xử lý). Framework tự động giảm tốc độ ghi dữ liệu để tránh tình trạng queue bị tràn.
Khi Nào Nên Sử Dụng Managed Kafka Services:
Nếu team của bạn nhỏ hoặc không có chuyên gia Kafka, hãy cân nhắc sử dụng Managed Kafka services như Confluent Cloud, AWS MSK (Managed Streaming for Kafka), hoặc Azure Event Hubs. Những dịch vụ này xử lý việc cài đặt, cấu hình, scaling, backup, và monitoring, cho phép team tập trung vào business logic thay vì vận hành hạ tầng.
Câu Hỏi Thường Gặp
Kafka và Redis có thể thay thế nhau không?
Không hoàn toàn. Hai công nghệ phục vụ mục đích khác nhau: Kafka tối ưu cho throughput cao và độ bền dữ liệu lâu dài, Redis tối ưu cho độ trễ cực thấp. Trong thực tế, chúng thường bổ trợ nhau thay vì cạnh tranh. Kafka xử lý ingest và xử lý luồng sự kiện quy mô lớn, Redis phục vụ lớp truy xuất nhanh cho người dùng cuối.
Redis Streams có thể thay thế Kafka không?
Redis Streams có persistence và consumer group tương tự Kafka, nhưng thiếu khả năng scale ngang (horizontal scaling) của Kafka. Nó không thể xử lý hàng triệu message mỗi giây trên một cluster bình thường. Redis Streams phù hợp cho hệ thống nhỏ đến trung bình nơi bạn cần persistence nhưng không cần khả năng scale Kafka.
Khi nào nên dùng Kafka thay vì Redis Pub/Sub?
Khi bạn cần: (1) lưu trữ và replay dữ liệu, (2) guaranteed message delivery ngay cả khi subscriber down, (3) xử lý hàng triệu sự kiện mỗi giây, (4) audit trail, hoặc (5) fan-out sang nhiều consumer group độc lập. Redis Pub/Sub không đáp ứng được các yêu cầu này.
Kiến trúc hybrid Kafka + Redis hoạt động như thế nào?
Kafka ingest dữ liệu từ nhiều nguồn và xử lý luồng sự kiện quy mô lớn. Sau khi xử lý với Kafka Streams hoặc Flink, kết quả tính toán (chẳng hạn như trending products, user profiles) được ghi vào Redis. API phía máy chủ đọc từ Redis để phục vụ người dùng cuối với độ trễ cực thấp. Mô hình này phân tách rõ vai trò: Kafka là data backbone, Redis là fast query layer.
Diskless Kafka năm 2026 là gì và tại sao quan trọng?
Diskless Kafka offload dữ liệu từ broker disk sang cloud object storage (như AWS S3 hay Azure Blob), broker chỉ giữ cache của dữ liệu gần đây. Cách này giảm chi phí cơ sở hạ tầng, cải thiện khả năng mở rộng đàn hồi, và đơn giản hóa disaster recovery. Nó đang thay đổi mô hình vận hành Kafka truyền thống từ "storage-centric" sang "compute-centric".
Không có câu trả lời tuyệt đối giữa Kafka hay Redis. Đây là hai công cụ bổ trợ nhau trong kiến trúc dữ liệu real-time hiện đại. Hãy chọn Kafka khi cần throughput cao, độ bền dữ liệu và event streaming quy mô lớn; chọn Redis khi ưu tiên độ trễ cực thấp và truy xuất tức thì. Trong nhiều hệ thống production thực tế năm 2026, câu trả lời tối ưu chính là kết hợp cả hai. Bắt đầu thiết kế kiến trúc của bạn bằng cách xác định rõ yêu cầu về latency, durability và scale, đó là nền tảng để ra quyết định kỹ thuật đúng đắn.
Khám Phá
Multi-Agent AI: Thiết Kế Kiến Trúc Hệ Thống Agent Thực Tiễn
Multi-Agent Pattern: Hướng dẫn chi tiết các mô hình phối hợp giữa Agent AI
GitHub Copilot vs Amazon Q Developer: So Sánh Công Cụ AI Lập Trình 2026
Multi-Agent AI 2026: Hướng Dẫn Xây Dựng Hệ Thống Theo Design Patterns